

人工智能和大型语言模型 (LLM) 目前非常流行,我们很高兴宣布推出一个深思熟虑的架构,可以从 LLM 中受益,同时仍然保持严格的数据驻留合规性。就像全球报告提供全球见解一样,公司希望运行全球人工智能来分析数据趋势,并使分析师能够根据提示更深入地研究数据。
全球人工智能利用来自多个国家的匿名数据进行操作
使用现场级匿名化技术,来自多个国家/地区的 InCountry 金库的数据可以输入到单个全球法学硕士中。名字和姓氏等数据字段可以匿名,法学硕士随后会对匿名数据进行标记。然后,LLM 可以在全局数据集上执行,而 LLM 用户无法查看受监管的数据字段。
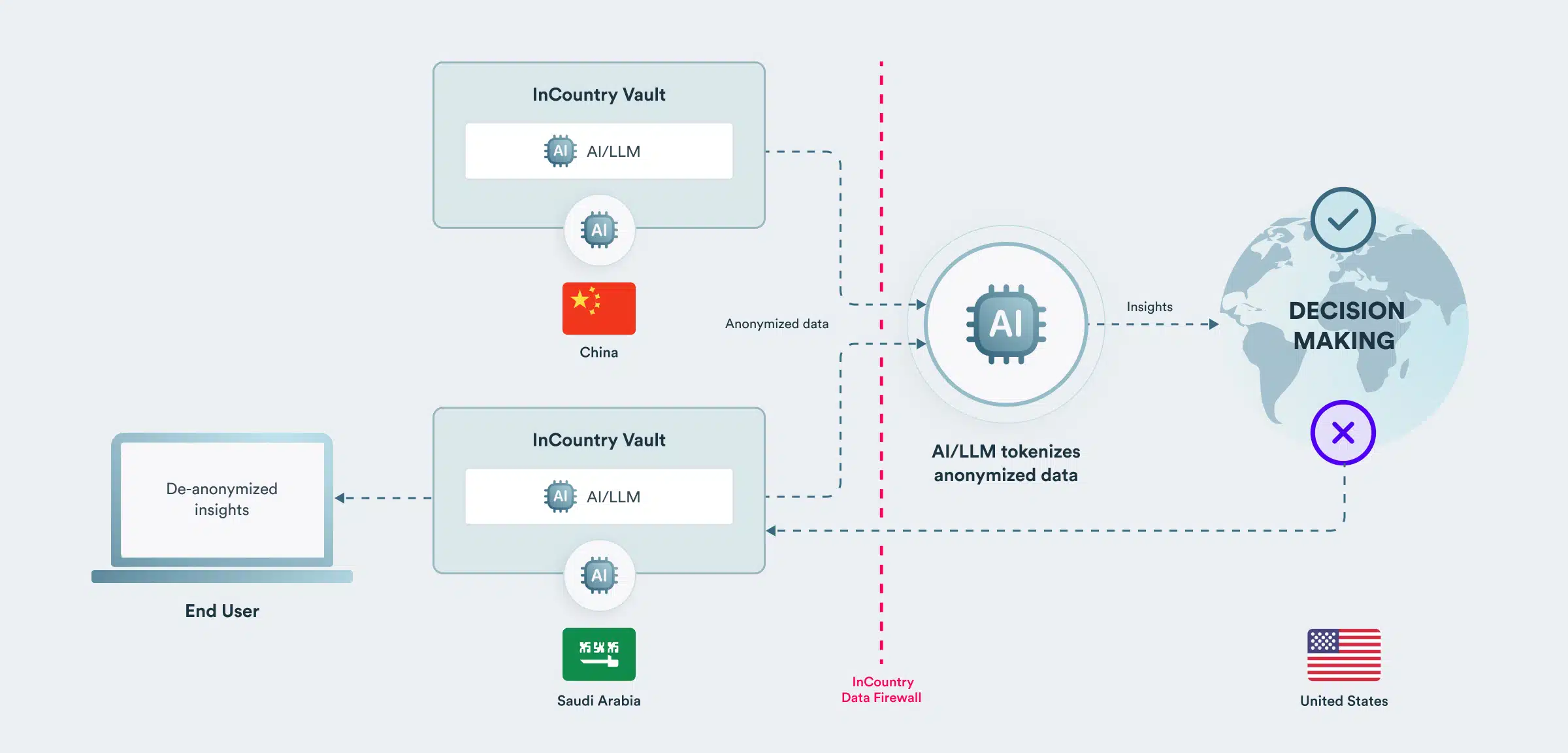
考虑一个医疗保健用例,其中全球人工智能检测来自多个国家的广泛数据集中的异常趋势。人工智能基于匿名患者数据进行操作,这些数据无法追溯到高度监管国家的个人。没有患者数据并不构成限制:对于大多数分析和见解,法学硕士不需要知道姓名和地址等信息。它需要了解血压、药物和健康结果等详细信息。
全球见解可以跨国家共享,因为它们不包含患者数据。例如,人工智能了解低血压和药物之间的意外不良反应。如果获得访问特定患者记录的适当授权,有关受影响患者的具体见解可以反馈给各个国家/地区的工作人员,并根据需要进行去匿名化。
本地人工智能使用本地数据进行操作
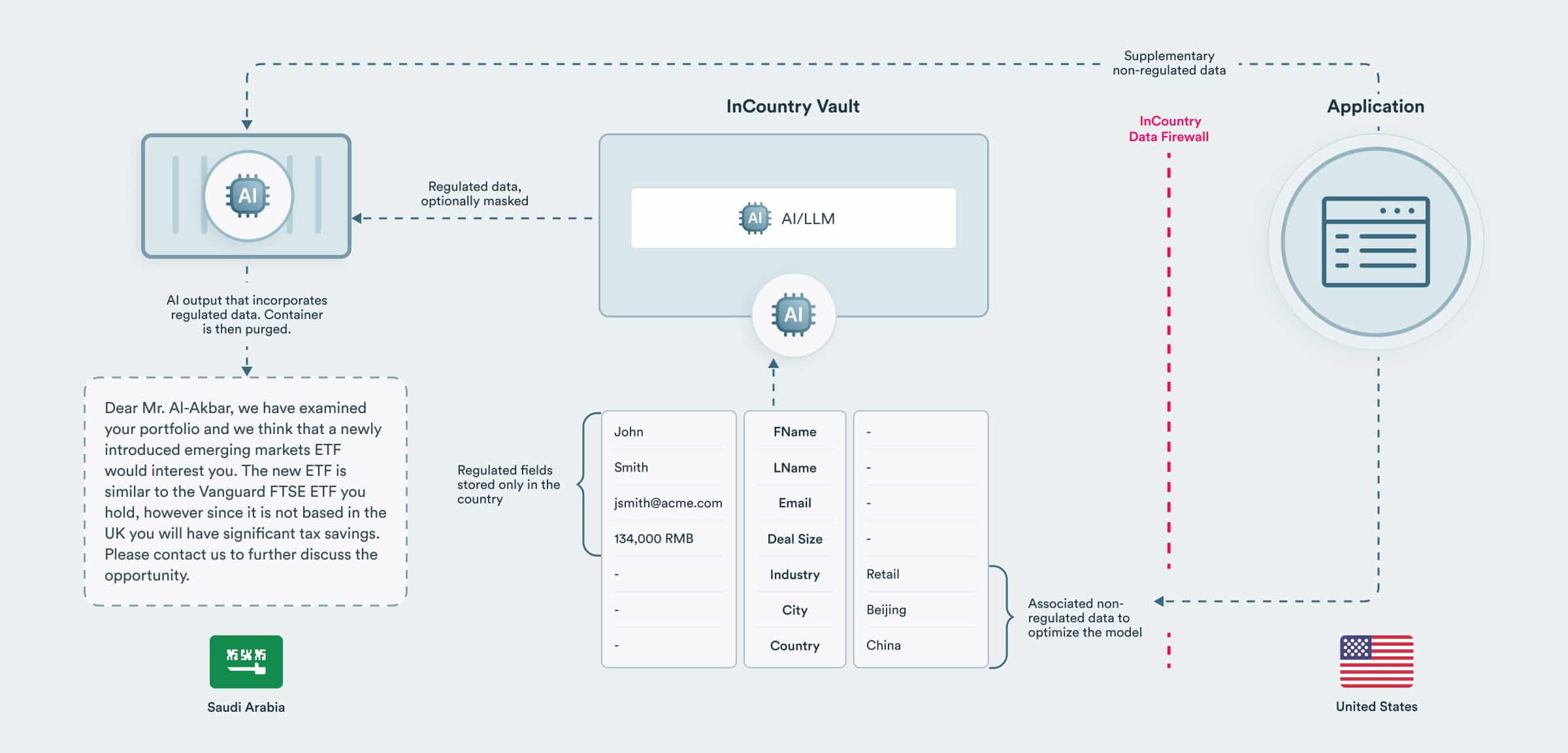
让法学硕士对详细的监管数据(例如健康或财务数据)进行操作有很多用例。然而,这种受到高度监管的数据通常无法导出到国外,即使数据是匿名的。
考虑一个金融服务用例,例如起草营销电子邮件活动,其中包含基于每个客户的投资组合的见解。法学硕士作为容器在一个国家/地区内完全部署,分析每个客户,并使用本地监管数据和外部非监管数据起草信件。
该容器部署到每个国家/地区,并直接集成来自每个国家/地区的 InCountry Vault 的数据。为了在每个国家/地区防止数据丢失,可以屏蔽输入 LLM 的数据,或者可以在履行职责后清除容器。
匿名化、数据隐私标记化和 LLM 标记化
需要考虑的一个有趣的方面是,当法学硕士对数据进行标记化时,为什么要对数据进行匿名化?首先,受监管的数据必须从来源国导出到法学硕士。此外,LLM对标记化的定义与数据隐私的定义有很大不同。对于法学硕士来说,令牌充当指向更大单元(例如单词)的指针,并且像字典一样,相同的令牌指向相同的单词并且可以轻松反转。在数据隐私定义中,令牌是不透明的,通常是指向原子值的一次性值。
因此,在 LLM 中,“Peter”始终标记为 322,但在数据隐私中,Peter Yared 记录中的 Peter 字段标记为 542355235,Peter Gabriel 记录中的 Peter 字段标记为 564322667。
在全球和本地使用人工智能来获取见解
虽然数据监管可能会使在全球数据集上部署人工智能变得更加麻烦,但 InCountry 的上述两种方法使得获得全球洞察并提供本地效益成为可能,同时保持受监管数据的完整数据驻留。