

Artificial intelligence and large language models (LLMs) are all the rage right now, and we’re excited to announce a thoughtful architecture to benefit from LLMs while still maintaining strict data residency compliance. Much like global reporting delivers global insights, companies want to run global artificial intelligence to analyze trends in data and enable analysts to delve deeper into data with prompts.
Global AI operating with anonymized data from multiple countries
Using field-level anonymization techniques, data from InCountry vaults in multiple countries can be fed into a single global LLM. Data fields like first and last names can be anonymized, and the LLM subsequently tokenizes the anonymized data. The LLM can then perform on a global data set, and LLM users do not have visibility into regulated data fields.
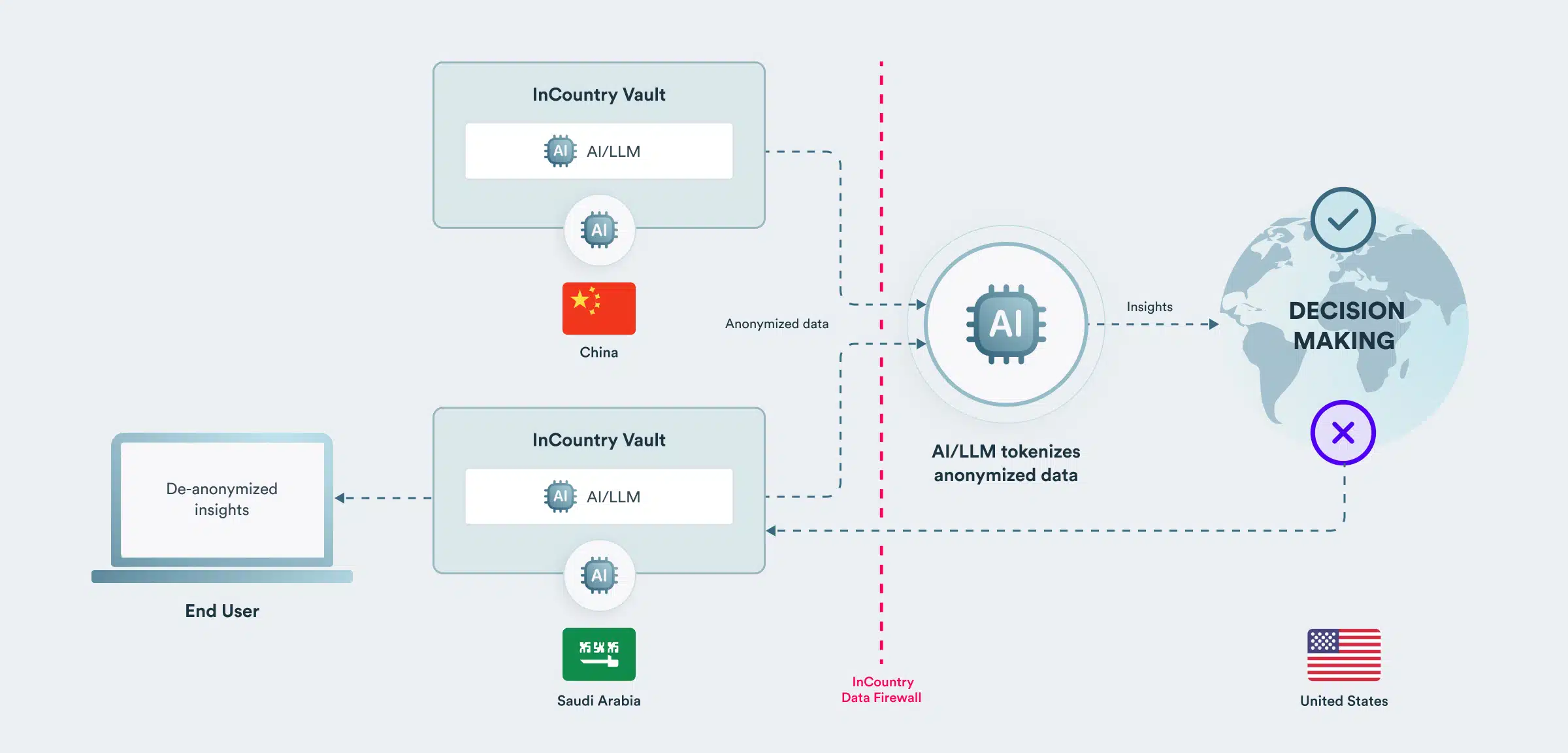
Consider a healthcare use case where a global AI detects anomaly trends across a broad dataset from several countries. The AI operates on anonymized patient data that can not be traced back to individuals in highly regulated countries. Not having patient data is not limiting: for most analyses and insights, an LLM does not need to know things like names and addresses. It needs to know details like blood pressure, medication, and health outcomes.
Global insights can be shared across countries since they do not contain patient data. For example, an AI learning about an unexpected adverse reaction between low blood pressure and medication. Specific insights about affected patients can be looped back to staff in individual countries and de-anonymized as needed, given the proper authorization to access a particular patient record.
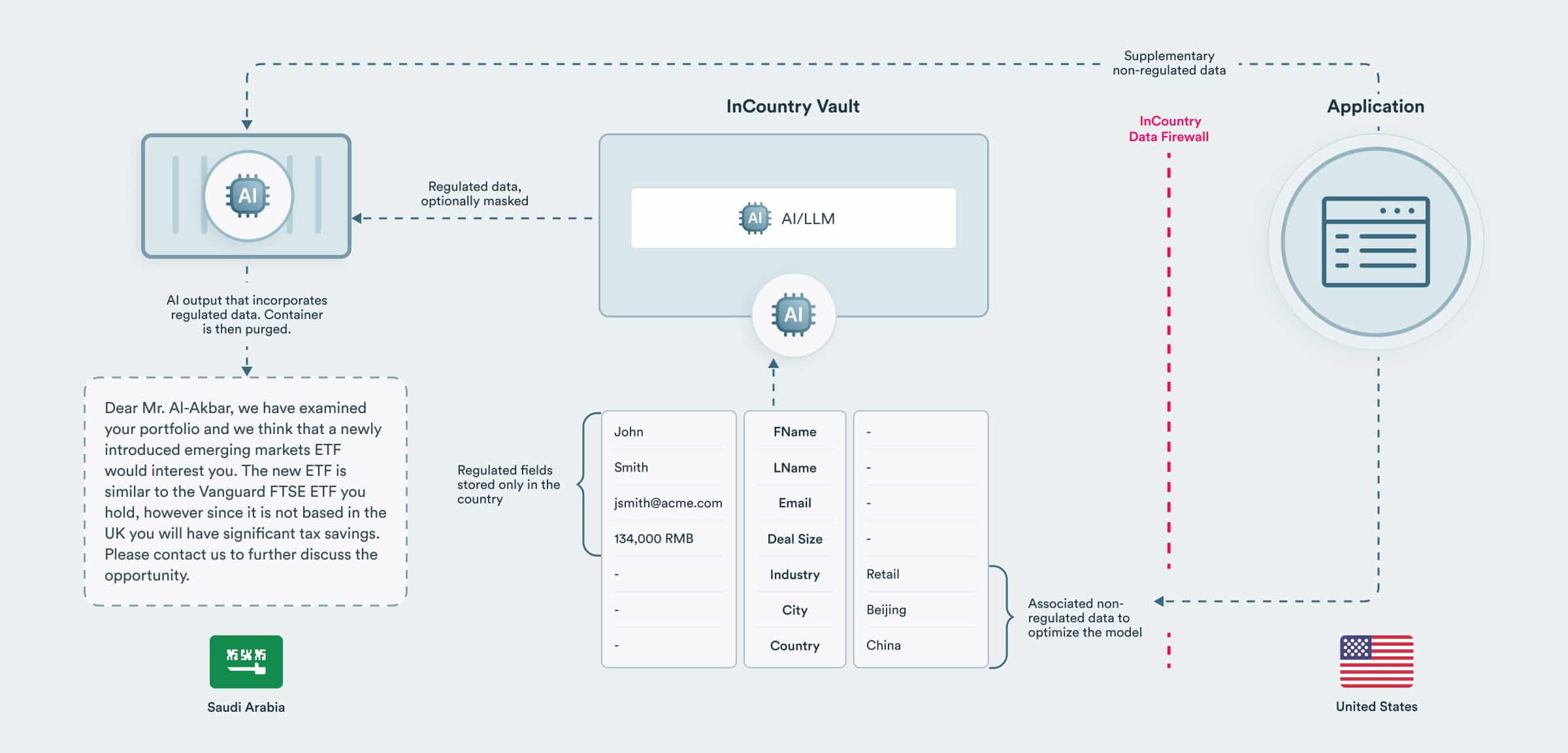
Local AI operating with local data
There are numerous use cases for having an LLM operate on detailed regulated data such as health or financial data. However, such highly regulated data often can not be exported outside of a country, even if the data is anonymized.
Consider a financial services use case, such as drafting a marketing email campaign incorporating insights based on each customer’s portfolio. An LLM is deployed fully within a country as a container, analyzes each customer, and drafts letters using both locally regulated data and external unregulated data.
The container is deployed into each country and integrates data directly from the InCountry Vault in each country. To maintain data loss prevention in each country, the data fed into the LLM can be masked, or the container can be purged after performing its duties.
Anonymization, data privacy tokenization, and LLM tokenization
An interesting facet to consider is why to anonymize data when an LLM tokenizes data? First, the regulated data would have to be exported from the source country to the LLM. In addition, the LLM’s definition of tokenization is quite different from the data privacy definition. For an LLM, a token serves as a pointer to a larger unit such as a word, and like a dictionary, the same token points to the same word and can be easily reversed. In the data privacy definition, a token is opaque and is generally a single-use value that points to an atomic value.
So in an LLM “Peter” is always tokenized as 322, but in data privacy, the Peter field in the Peter Yared record is tokenized as 542355235 and the Peter field in the Peter Gabriel record is tokenized as 564322667.
Use AI globally and locally to gain insights
While data regulations can make deploying artificial intelligence on global data sets a little more cumbersome, InCountry’s above two approaches make it possible to gain global insights and deliver local benefits while maintaining full data residency for regulated data.